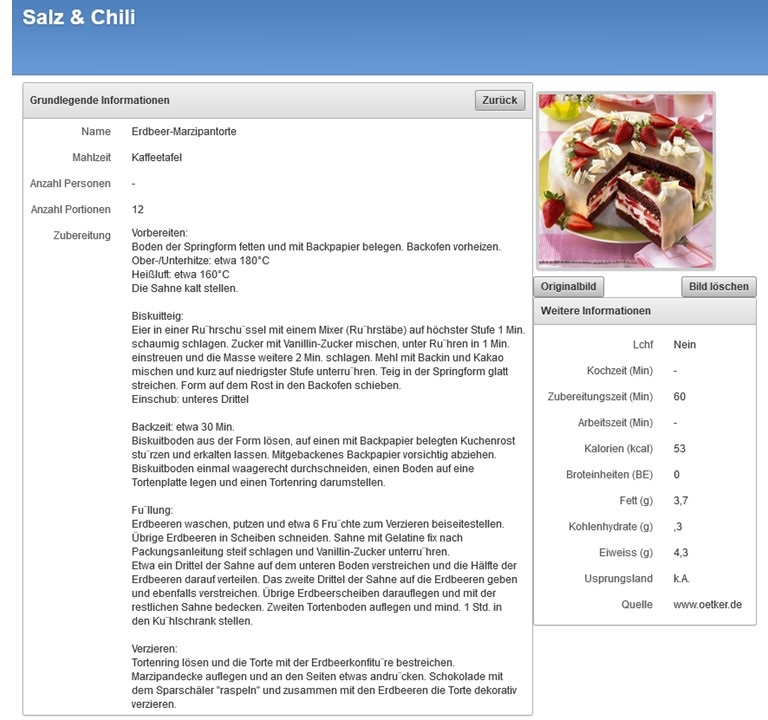
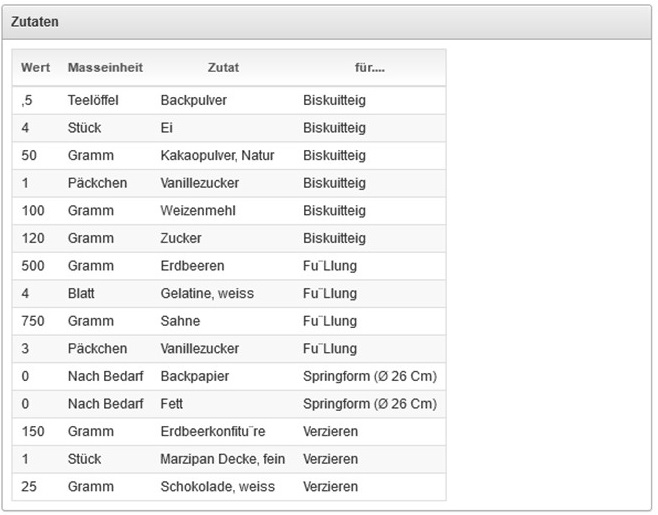
Alles begann damit, dass meine Frau nach einem Unfall strikte Diät einhalten musste: LCHF – Low Carb High Fat . Es half meiner Frau. Nur…die Rezepte waren rar gesät. Mal gabs ein Rezept in einer Zeitung, mal online. In Kochbüchern gab es auch mal zwei oder drei. Ergebnis: Zwei Dutzend Kochbücher und 20 Rezepte, jede Woche beim Finden des Speiseplans für die nächste Woche lag der Küchentisch voller Bücher. Das geht besser.
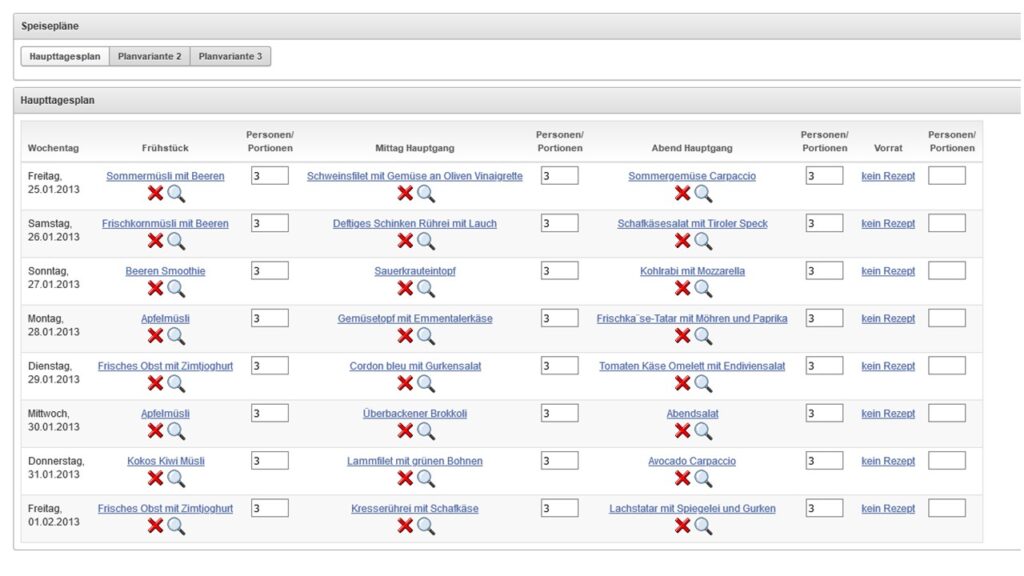
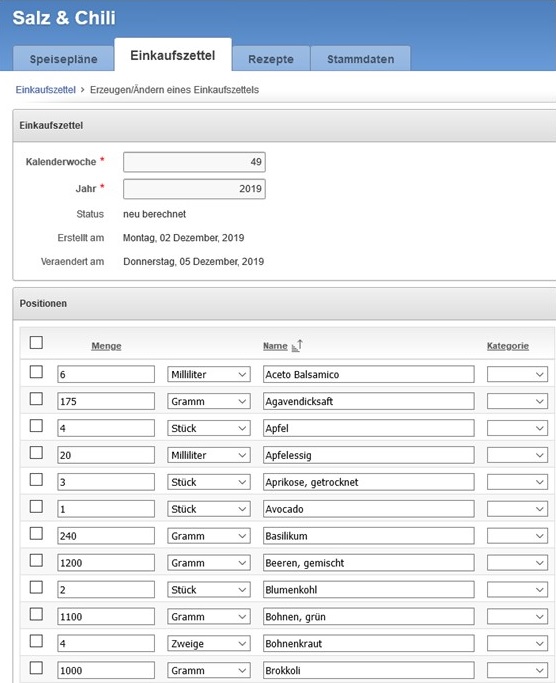
Also habe ich eine Datenbank erzeugt, eine Datenmodell erstellt und eine APEX-Anwendung entwickelt, um Rezepte relational abspeichern, um einen Wochenspeiseplan erstellen und um aus diesem Speiseplan den Einkaufszettel generieren zu können – und es funktioniert.
Als dann ORACLE mit seinem freien Cloud-Service für autonomous Databases startete, habe ich mir überlegt, alles in die Cloud zu bringen. Das hat viele Vorteile: Mein Service ist überall erreichbar, ich kann von überall dran arbeiten, ich brauche mich nicht um Upgrades des RDBMS oder der APEX-Entwicklungsumgebung oder der Infrastruktur zu kümmern. Also los! Das Einrichten eines Accounts und einer kostenlosen Datenbank ging in 30 Minuten. Cool, ich brauche dafür manuell länger. An die Datenbank von den Entwicklungstools auf meinem Rechner heranzukommen dauerte etwas länger. Überall Sicherheitseinrichtungen: Passwörter müssen richtig lang sein, die Credentials für die DB bekommt man nur mit Key und dann auch nur mit einem Wallet. Sicherheit nervt einen Entwickler und DBA wie mich, aber objektiv gesehen muss es sein und nach dem was ich im Oracle-Cloud-Service so sicherheitstechnisch sehe, sind die Daten und Prozesse mindestens genauso sicher wie auf den Firmenrechner im eigenen Datacenter.
Um Daten in die Datenbank zu importieren, braucht man einen Object Store, dort kann man den Dump hochladen natürlich auch mit Key und danach kann man den Dump mit dem Instant Client in die Datenbank laden. Auch Mailing von der Cloud aus ist komplett abgesichert, die Absenderadresse muss registriert werden, ohne dies kein Mailversand. Allerdings geht das nicht im kostenlosen Bereich, obwohl es anders in der Doku steht. Also musste ich meine APEX-Rezepte-App erstmal umbauen, und weil ich schon dabei war habe ich es multiuserfähig gemacht.
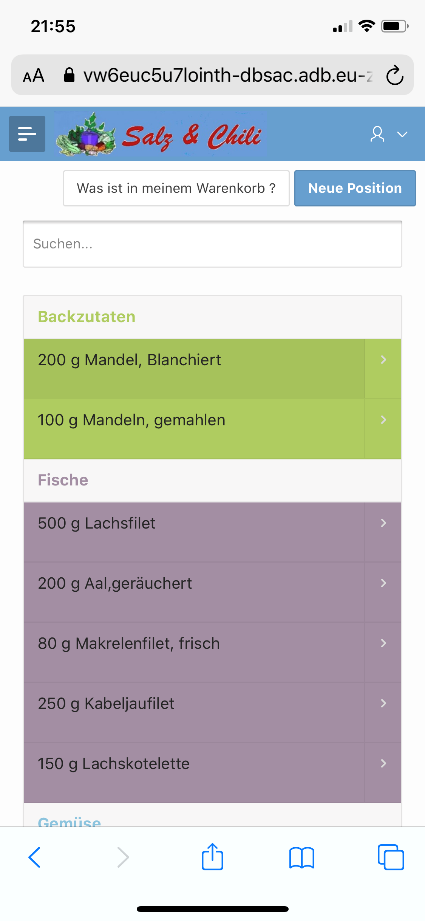
Somit ist es nun möglich, dass jeder die App benutzen kann (http://www.salz-und-chili.de), nachdem man sich dort als User registriert hat. Es sind ca. 400 Rezepte drin, man kann aber auch seine eigenen eingeben. Zu den einzelnen Schritten gibt es unter dem entsprechenden Button Hilfe. Und um den Einkaufszettel auf dem Smartphone mit zum Einkaufen zu nehmen, gibt es eine eigene APEX mobile App. Diese kann man als App auf dem Homescreen jedes Smartphones ablegen.
Vielleicht hat der eine oder andere Lust, es auszuprobieren. Fehler und Verbesserungsvorschläge gerne an mich. Ich werde weiter ab den Apps entwickeln, verbessern und erweitern. Und so wie es aussieht, bleibt es dabei, alles 100% ORACLE.
Datenbanken sind ja dazu da, Daten zu speichern. Die Daten werden in irgendeiner Form verarbeitet. Das kann sein vor dem Speichern in der Datenbank, in dem die Daten von anderen Systemen zusammengesammelt und – gestellt werden und dann in die Datenbank geladen werden. Es kann auch sein, dass die Daten innerhalb der Daten weiter verarbeitet, z.B. aggregiert, werden. Diese Verarbeitung übernimmt ein Batch, der vorzugsweise nachts läuft und im Idealfall für vor den Bürozeiten beendet ist, so dass pünktlich zum Arbeitsbeginn die akteullen Daten zur Verfügung stehen.
So ein Batch kann aus verschiedenen Scripten auf unterschiedlichen Servern bestehen, aber auch aus einem Script innerhalb der Datenbank. Das können SQL-Scripte sein, aber auch Programmcode, also in ORACLE’s Programmiersprache PL/SQL geschrieben. Wichtig für so ein Batch sind Protokolle über den Ablauf. Darin kann der DevOps-Engineer sehen, ob alles fehlerfrei verarbeitet wurde, wie lange der Batch gedauert usw.
Protokollieren ist in einem Shellscript sehr einfach, man lenkt echo-Ausgaben zwischen den verarbeitenden Scritten in ein Logfile aus – fertig. Aber wie geht das aus der Datenbank heraus? Im Normalfall, startet man sqlplus und für darin entweder ein SQL-Script, also irgendwelche Insert-Update-Delete-Sequenzen, aus oder man startet ein PL/SQL-Schnipsel, entweder als stored procedure oder function – standalone oder in einem Package hinterlegt – oder als anonymen Block. Die Ausgaben bei solchen Scripten sind nur soundsoviel Rows inserted, updated oder deleted oder „function (oder procedure) successful finished oder es gab irgendeinen Fehler.
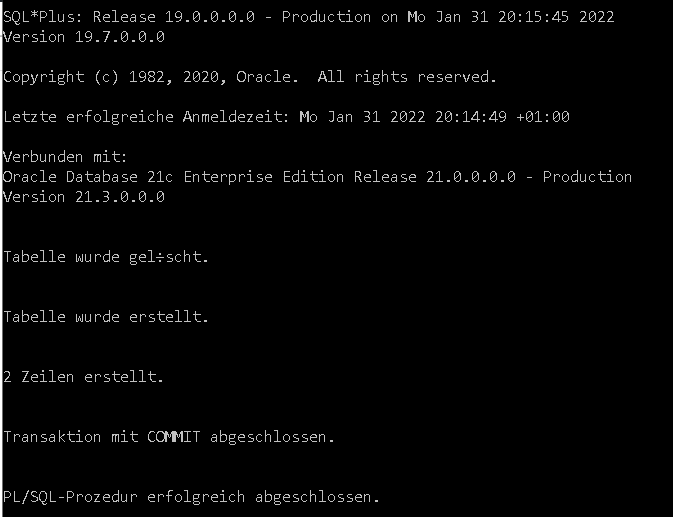
Log-Einträge beim Ausführen eines Scripts in sqlplus
Für SQL-Scripts mag das vielleicht reichen, aber bei der Ausführung von etwas komplexeren PL/SQL-Objekten möchte man schon wissen, was gerade wie verarbeitet wurde oder wo die Verarbeitung gerade steht usw. D.h. man braucht Funktionen oder Prozeduren, die im PL/SQL-Code aufgerufen werden. Man könnte DBMS_OUTPUT verwenden.Allerdings würde dann alles in der sqlplus-Session ausgegeben werden. Und nicht alle Datentypen können mit DBMS_OUTPUT ausgegeben werden. Und wenn man nicht die richtigen Einstellungen hat, sind die Ausgaben futsch. Das Gleiche gilt für Ausgaben in Prozeduren, die als Job ausgeführt werden.
Deswegen musste ich mir etwas anderes überlegen, und dabei ist der logFileMgr entstanden. Dies ist ein Package, mit dem man in definierte Logfiles, die irgendwo auf dem Datenbankserver liegen können, schreiben kann. Zusätzlich kann man seine Ausgaben in verschiedene Log Levels unterteilen, je nach Bedeutung der Ausgabe und ähnlich den Log Levels in Linux:
Level 1 – „alert“
Level 2 – „critical“
Level 3 – „error“
Level 4 – „warning“
Level 5 – „notice“
Level 6 – „information“
Level 7 – „debug“
Level-1-Meldungen sind also Meldungen, die schwerwiegende Fehlerzustände anzeigen, Level-7-Meldungen sind dafür da, um Debugmeldungen auszugeben. Nun kann man für einen PL/SQL-Prozedur-Lauf in einem Konfigurationsfile ein Log Level angeben, z.B: 4 (warning). Damit werden alle Protokollausgaben grösser als 4 ignoriert, alle Ausgaben mit einem Log Level kleiner oder gleich 4 werden ausgegeben. Auf diese Art und Weise ist es nun möglich, Stored Procedures zu entwickeln, die alle Ausgaben von kritisch bis Debug enthalten. Der DevOps-Engineer, der den Betrieb verantwortet, kann nun den für ihn im Betrieb ausreichenden Log Level in der Konfiguration setzen, z.B. 5 (notice). Sollte es beim Ausführen der Prozedur zu Fehlern kommen, kann der Log Level einfach auf 7 (debug) gesetzt und anhand der nun ausgegebenen Debug-Informationen der Fehler gesucht werden.
Die Konfigurationsdatei, in der man die Logfiles und das Ausgabeverhalten beschreibt, kann ebenfalls irgendwo auf dem Datenbankserver, egal ob UNIX/Linux oder Windows, abgelegt werden.
###################################
# Description:
# ============
# Example for a Log Configuration
#
# File: logging.cfg
# Author: Andy Kielhorn
# Company: AkiCom
###################################
#
# Logging for PL/SQL batch TESTLOG
#
TESTLOG_LOGLEVEL=7
TESTLOG_LOGFILE=/opt/oracle/admin/log/testlog.log
TESTLOG_LOGFORMAT=ALL
#
# Logging for PL/SQL module WATCHDOG
#
WATCHDOG_LOGLEVEL=4
WATCHDOG_LOGFILE=/opt/watchdog/log/watchDogDeamon.log
WATCHDOG_LOGFORMAT=ALL
Die Datei kann mehrere Konfigurationen für verschiedene PL/SQL-„Batches“ enthalten. Pro „Batch“ oder Modul gibt es drei Parameter, die immer mit dem Namen des Batches oder dem Modul beginnen.
Log Level
Mit dem Parameter der Form <Modulname>_LOGLEVEL= [1|2|3|4|5|6|7] stellt man den Log Level ein. D.h. wie schon beschrieben, es werden alle Ausgaben mit einem Log Level, der kleiner oder gleich dem hier angegebenen ist, ausgegeben.
Logfile
Mit dem Parameter der Form <Modulname>_LOGFILE=<Log File mit Pfad> gibt man den Namen und den Speicherort des Logfiles auf dem Server an.
Logformat
Der Parameter <Modulname>_LOGFORMAT=[ALL|NAME|TIME|HOUR|DAY|SHORT] gibt das Ausgabeformat für den Zeitstempel auf der linken Seite der Ausgabe fest
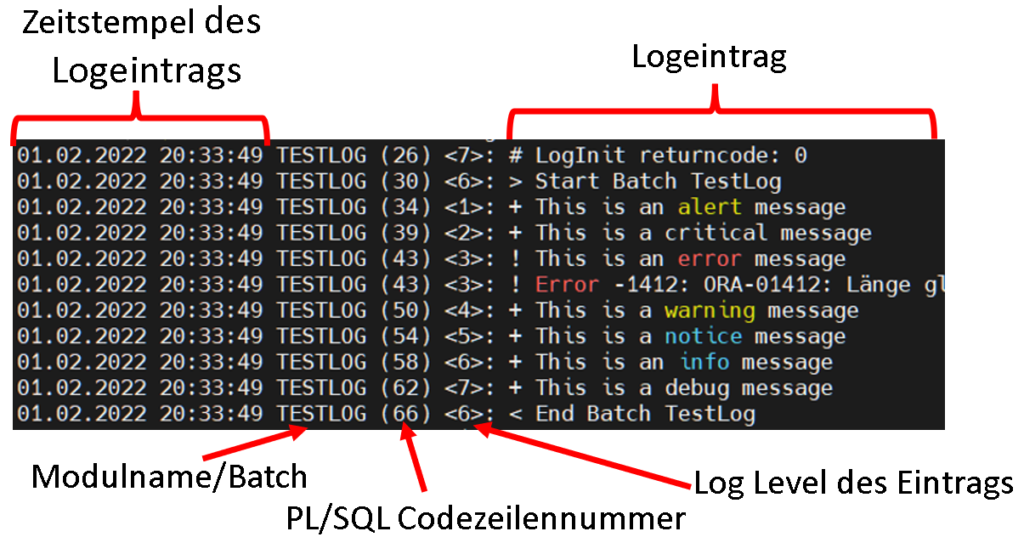
Log-Ausgaben mit logFileMgr
Bei Logformat NAME wird kein Zeitstempel ausgegeben, bei HOUR und SHORT wird kein Datum ausgegeben, während bei DAY die Uhrzeit fehlt.
Um das Logging zu starten muss die Funktion logInit aufgerufen werden, dabei muss der Pfad zur Konfigurationsdatei, der Name der Konfigurationsdatei und der Name des Moduls, dessen Konfiguration geladen werden soll. Danach stehen verschiedene writeLog-Prozeduren zur Verfügung, mit denen man Log-Einträge in der Protokolldatei erzeugen kann. Zu dem gibt es noch eine Prozedur raiseError, die einen Log-Eintrag erzugt und danach einen Fehler „raised“.
Alle Log Level sowie alle Log-Formate sind als Konstanten in der Package Spezifikation hinterlegt.
CREATE OR REPLACE PACKAGE logFileMgr IS
/* *****************************************************************************
* Description
* ============
* This package enables logging in UNIX files system
*
* File: pkg_akitools_logfilemgr_ph.sql
* Modified at: $Date: 2020-01-01 08:00:00 +0200 (Mi, 01 Jan 2020) $
* Checked in by: $Author: AKielhorn $
* Revision: $Revision: 100 $
* Author: Andy Kielhorn
* Company: AkiCom
*****************************************************************************
*/
/* ====================================================================================
Constants
=====================================================================================
************************************************************************************
L O G G I N G L E V E L S
The logging system introduces different levels (logging levels) of the protocol
scope. These are based on the logging levels of the operating system Linux and
are defined in the following.
It applies that all messages will be written to logfile that correspond to the
set level and the one below it.
For example you set Level 4, so all messages from level 1 to level 4 will be
writtento logfile
************************************************************************************
Level 1 - "alert"
With this logging level, a module only outputs messages that are acted upon
immediately otherwise the system will suffer a production standstill.
This message must be forwarded to the person responsible for the system
immediately.
*/
c_alert CONSTANT PLS_INTEGER := 1;
/* Level 2 - "critical"
Messages of this logging level indicate a critical status.
Here, too, the person responsible for the system should be informed.
*/
c_critical CONSTANT PLS_INTEGER := 2;
/* Level 3 - "error"
Messages with this logging level log errors in a module.
*/
c_error CONSTANT PLS_INTEGER := 3;
/* Level 4 - "warning"
The messages classified by the module as warnings are logged here.
*/
c_warning CONSTANT PLS_INTEGER := 4;
/* Level 5 - "notice"
In this level, normal but important information of the modules are logged
*/
c_notice CONSTANT PLS_INTEGER := 5;
/* Level 6 - "information"
This level denotes simple information of no major importance, which
can also be ignored.
*/
c_info CONSTANT PLS_INTEGER := 6;
/* Level 7 - "debug"
Debug messages are the least relevant messages and are the most important
for checking freshly written software for possible errors or for tracking down
exploited by errors in existing software.
*/
c_debug CONSTANT PLS_INTEGER := 7;
/* Options for the left site of logging message */
/* only module name */
logFormatName CONSTANT VARCHAR2(10) := 'NAME';
/* only day and night */
logFormatTime CONSTANT VARCHAR2(10) := 'TIME';
/* only time */
logFormatHour CONSTANT VARCHAR2(10) := 'HOUR';
/* only day */
logFormatDay CONSTANT VARCHAR2(10) := 'DAY';
/* all */
logFormatAll CONSTANT VARCHAR2(10) := 'ALL';
/* only name and time -> short*/
logFormatShort CONSTANT VARCHAR2(10) := 'SHORT';
/* Errors that can occured during file operations */
logInvalidPath CONSTANT NUMBER := -1;
logInvalidMode CONSTANT NUMBER := -2;
logInvalidFileHandle CONSTANT NUMBER := -3;
logInvalidOperation CONSTANT NUMBER := -4;
logReadError CONSTANT NUMBER := -5;
logWriteError CONSTANT NUMBER := -6;
logInternalError CONSTANT NUMBER := -7;
logNoCFGFile CONSTANT NUMBER := -8;
logLogConfigFound CONSTANT NUMBER := -9;
logWrongOpenMode CONSTANT NUMBER := -10;
logNoDataFound CONSTANT NUMBER := -100;
/* ******************************************************************************************
* Function: logInit
* Description: initialisation of logging,
* read logging configuration
*
* Parameter: i_moduleName - Name of module logging is initiate for
* i_logCfgPath - Path of Logging configuration file
* i_logCfgFile - Logging configuration file
*
* Returnvalue: 0 = No errors, else Error
******************************************************************************************
*/
FUNCTION logInit( i_moduleName IN VARCHAR2,
i_logCfgPath IN VARCHAR2 DEFAULT '/tmp',
i_logCfgFile IN VARCHAR2 DEFAULT 'logging.cfg') RETURN NUMBER;
/* ********************************************************************************************************
* Procedure: writeLog
*
* Description: procedure logs all given information in table message_log
*
* Parameters: i_v_moduleName - name of calling module
* i_n_moduleCodeLine - line number in code of calling module
* for messages with given parameters
* i_n_loggingLevel - logging level of message
* i_v_messageText - free style message
* i_b_setAppInfo - TRUE = set application info (DBMS_APPLICATION_INFO)
********************************************************************************************************
*/
PROCEDURE writeLog (i_v_moduleName IN VARCHAR2,
i_n_moduleCodeLine IN NUMBER,
i_n_loggingLevel IN PLS_INTEGER,
i_v_messageText IN VARCHAR2,
i_b_setAppInfo IN BOOLEAN DEFAULT FALSE);
/* ********************************************************************************************************
* Procedure: writeLog
* Description: Procedure logs all given information in table message_log
*
* Parameters: i_n_moduleName - name of calling module
* i_n_moduleCodeLine - line number in code of calling module
* for messages with given parameters
* i_n_loggingLevel - logging level of message
* i_v_messageText - free style message
* i_n_dbErrorID - Error-ID of DB
* i_v_dbErrorText - error message
********************************************************************************************************
*/
PROCEDURE writeLog (i_v_moduleName IN VARCHAR2,
i_n_moduleCodeLine IN NUMBER,
i_n_loggingLevel IN PLS_INTEGER,
i_v_messageText IN VARCHAR2,
i_n_dbErrorID IN NUMBER,
i_v_dbErrorText IN VARCHAR2);
/* ********************************************************************************************************
* Procedure: raiseError
* Description: Procedure logs all given information in table message_log and raise DB error
*
* Parameters: i_n_moduleName - name of calling module
* i_n_moduleCodeLine - line number in code of calling module
* for messages with given parameters
* i_n_loggingLevel - logging level of message
* i_v_messageText - free style message
* i_n_dbErrorID - Error-ID of database
* i_v_dbErrorText - error message
********************************************************************************************************
*/
PROCEDURE raiseError (i_v_moduleName IN VARCHAR2,
i_n_moduleCodeLine IN NUMBER,
i_n_loggingLevel IN PLS_INTEGER,
i_v_messageText IN VARCHAR2,
i_n_dbErrorID IN NUMBER,
i_v_dbErrorText IN VARCHAR2);
END LogFileMgr;
Das Schema, das den logFileMgr enthält, benötigt SELECT-Zugriff auf die View DBA_DIRECTORIES, ausserdem das Recht CREATE ANY DIRECTORY. Damit das Package datenbankweit benutzt werden kann, sollte man ein public Synonym für das Package erzeugen und die Execute-Rechte an Public vergeben. Nun kann man die Funktionen des logFileMgr in seinem eigenen PL/SQL-Quellcode benutzen, wie z.B. hier:
CREATE OR REPLACE PROCEDURE testLog
IS
/* *****************************************************************************
* Description
* ============
* This procedure shows how to use LogFileMgr
*
* File: proc_akitools_testLog.sql
* Modified at: $Date: 2020-01-01 08:00:00 +0200 (Mi, 01 Jan 2020) $
* Checked in by: $Author: AKielhorn $
* Revision: $Revision: 100 $
* Author: Andy Kielhorn
* Company: AkiCom
*****************************************************************************
*/
retCode NUMBER;
BEGIN
retCode :=
logFileMgr.logInit (i_moduleName => $$PLSQL_UNIT,
i_logCfgPath => '/opt/oracle/admin/log/config',
i_logCfgFile => 'logging.cfg');
logFileMgr.writeLog (
i_v_moduleName => $$PLSQL_UNIT,
i_n_moduleCodeLine => $$PLSQL_LINE,
i_n_loggingLevel => logFileMgr.c_debug,
i_v_messageText => '# LogInit returncode: ' || retCode);
logFileMgr.writeLog (i_v_moduleName => $$PLSQL_UNIT,
i_n_moduleCodeLine => $$PLSQL_LINE,
i_n_loggingLevel => logFileMgr.c_info,
i_v_messageText => '> Start Batch TestLog');
logFileMgr.writeLog (i_v_moduleName => $$PLSQL_UNIT,
i_n_moduleCodeLine => $$PLSQL_LINE,
i_n_loggingLevel => logFileMgr.c_alert,
i_v_messageText => '+ This is an alert message');
logFileMgr.writeLog (
i_v_moduleName => $$PLSQL_UNIT,
i_n_moduleCodeLine => $$PLSQL_LINE,
i_n_loggingLevel => logFileMgr.c_critical,
i_v_messageText => '+ This is a critical message');
logFileMgr.writeLog (i_v_moduleName => $$PLSQL_UNIT,
i_n_moduleCodeLine => $$PLSQL_LINE,
i_n_loggingLevel => logFileMgr.c_error,
i_v_messageText => '! This is an error message',
i_n_dbErrorID => -1412,
i_v_dbErrorText => SQLERRM (-1412));
logFileMgr.writeLog (
i_v_moduleName => $$PLSQL_UNIT,
i_n_moduleCodeLine => $$PLSQL_LINE,
i_n_loggingLevel => logFileMgr.c_warning,
i_v_messageText => '+ This is a warning message');
logFileMgr.writeLog (i_v_moduleName => $$PLSQL_UNIT,
i_n_moduleCodeLine => $$PLSQL_LINE,
i_n_loggingLevel => logFileMgr.c_notice,
i_v_messageText => '+ This is a notice message');
logFileMgr.writeLog (i_v_moduleName => $$PLSQL_UNIT,
i_n_moduleCodeLine => $$PLSQL_LINE,
i_n_loggingLevel => logFileMgr.c_info,
i_v_messageText => '+ This is an info message');
logFileMgr.writeLog (i_v_moduleName => $$PLSQL_UNIT,
i_n_moduleCodeLine => $$PLSQL_LINE,
i_n_loggingLevel => logFileMgr.c_debug,
i_v_messageText => '+ This is a debug message');
logFileMgr.writeLog (i_v_moduleName => $$PLSQL_UNIT,
i_n_moduleCodeLine => $$PLSQL_LINE,
i_n_loggingLevel => logFileMgr.c_info,
i_v_messageText => '< End Batch TestLog');
EXCEPTION
WHEN OTHERS THEN
logFileMgr.raiseError(i_v_moduleName => $$PLSQL_UNIT,
i_n_moduleCodeLine => $$PLSQL_LINE,
i_n_loggingLevel => logFileMgr.c_error,
i_v_messageText => '! This is an error message',
i_n_dbErrorID => SQLCODE,
i_v_dbErrorText => SQLERRM);
END testLog;
Die Prozedur schreibt Log-Einträge in das Protokoll /opt/oracle/admin/log/testlog.log.
01.02.2022 20:33:49 TESTLOG (26) <7>: # LogInit returncode: 0
01.02.2022 20:33:49 TESTLOG (30) <6>: > Start Batch TestLog
01.02.2022 20:33:49 TESTLOG (34) <1>: + This is an alert message
01.02.2022 20:33:49 TESTLOG (39) <2>: + This is a critical message
01.02.2022 20:33:49 TESTLOG (43) <3>: ! This is an error message
01.02.2022 20:33:49 TESTLOG (43) <3>: ! Error -1412: ORA-01412: Länge gleich Null ist für diesen Datentyp nicht gestattet
01.02.2022 20:33:49 TESTLOG (50) <4>: + This is a warning message
01.02.2022 20:33:49 TESTLOG (54) <5>: + This is a notice message
01.02.2022 20:33:49 TESTLOG (58) <6>: + This is an info message
01.02.2022 20:33:49 TESTLOG (62) <7>: + This is a debug message
01.02.2022 20:33:49 TESTLOG (66) <6>: < End Batch TestLog
Der logFileMgr zusammen mit einem Installationsscript, der Testprozedur und einem Beispiel für die Log-Konfiguration können im Download-Bereich heruntergeladen werden. Ich hoffe, dass der logFileMgr an der einen oder anderen Stelle eingesetzt wird und nützlich ist. Über ein Feedback und Verbesserungsvorschläge würde ich mich freuen.
Seit mehr als 25 Jahren beschäftige ich mich mit Datenbanken. Klar gab es damals eine Reihe von Datenbanken, dBase, FoxPro, Postgres, Informix usw.. Kommerziell haben sich aber nur DB2 von IBM, MS-SQL von Microsoft, Teradata und vor allen die Datenbank von ORACLE durchgesetzt.
Ich habe mich hauptsächlich mit ORACLE beschäftigt und damit so ziemlich jede Aufgabe gelöst. Natürlich habe ich auch mit anderen Datenbanken gearbeitet: ein Data Warehouse mit Teradata, TimesTen für Echtzeit-Datenerfassung, MySQL für einen Webshop usw. Meinen Kunden habe ich auch immer versucht, die Datenbank vorzuschlagen, die für ihr Vorhaben mir am besten geeignet schien, halt die mit dem besten Kosten-Nutzen-Verhältnis. Meist war es ORACLE, weil alles andere kam kaum in Frage, DB2 gabs nur für Grossrechner oder teure AIX-Maschinen, MS-SQL war auch nicht gewünscht, weil man lieber UNIX-Server als Windows-Server haben wollte oder die Anwendung lief damit nicht. TimesTen und Terradata waren zu speziell und MySQL war (noch) nicht „business-ready“. Seit mehreren Jahren drängen nun viele andere Datenbanken in den Markt: PostgreSQL, MariaDB, Mongo-DB, NO-SQL-Datenbanken, Cassandra und auch Datenbankservices für verschiedene Zwecke in der AWS-Cloud usw..
Eigentlich für mich als Datenbank-„Fuzzi“ eine komfortable Situation, die Auswahl ist nun grösser und ich kann einem Kunden mehrere Varianten vorschlagen. Allerdings kam mit den Datenbankalternativen eine gewisse Stimmungsmache gegen ORACLE auf. Schon davor kam Diskussionen und Skepsis auf, diese wurde von Jahr zu Jahr heftiger und schlug in einen fast schon feindlichen ja aggressiven Ton um. Mir selbst schlug diese Stimmungsmache und Aggressivität entgegen bei einem festen Engagement, bei dem ich für das Unternehmen den ORACLE-Stack neu konzipieren, härten und optimieren sollte. Allein nur weil ich im ORACLE-Umfeld tätig war, schlug mir von meinem Chef und danach auch von einigen Kollegen erst Skepsis und dann Feindseligkeit entgegen.
Was ist da passiert? Aus meiner Sicht begann es eigentlich recht harmlos: Mit dem Aufkommen von objektorientierter Programmierung und JAVA kollidierte die OO-Sicht mit der relationalen Speicherung von Daten in der Datenbank. Man entwickelte Klassen für die Transformation zwischen beiden Welten, wie z.B. Hibernate. Diese waren dann die Persistenzschicht, also der Layer, der die Daten abspeichert. Damit wurde der Umgang mit Datenbanken abstrahiert. Die Entwickler verloren den Fokus auf ein performantes Datenmanagement, getreu dem Motto „das macht die Java-Klasse“. Meines Erachtens leider eine fatale Sicht bei den immer grösser werdenden Datenvolumen, die verarbeitet werden müssen. Hinzu kam, dass man bei der Entwicklung uns Datenbanktypen aussen vorgelassen hat, auch weil die „Java-Klasse macht das ja“…. Also wurden dann die fertigen JAVA-Apps für den Betrieb „über den Zaun geworfen“. Naja und dann kamen halt im Betrieb die üblichen Probleme, die mit steigendem Datenvolumen so einhergehen: Lange Wartezeiten und Timeouts. Was kannst du da als DBA (Datenbankadministrator) machen? Wenn man Glück hat, hilft ein Index oder zwei. An die Query kommt man meist nicht ran, die ist im JAVA-Quellcode. Mit Chance bekomme ich die Query vom Entwickler oder aus dem Trace. Dann kann ich diese optimieren und den optimalen Execution Plan der ursprünglischen Query unterschieben (Ja das geht in ORACLE, und so weit ich weiss nur in ORACLE). Ich habe mal für einen Versandhändler gearbeitet und dieser wollte auf seiner Online-Plattform mit einem Gewinnspiel E-Mail-Adressen für seine Newsletter sammeln. Der Entwickler, man nannte ihn „Gott“, weil er virtuos in JAVA programmieren konnte, hatte die Komponente erstellt und immer in der Nacht von Donnerstag auf Freitag wurde so etwas deployed. Ja und um 11 Uhr vormittags stand der Shop. Was war passiert ? Vor dem Eintragen der Mailadresse in eine Tabelle wurde geprüft, ob diese Mailadresse schon eingetragen war. Und auf der Tabelle war kein Index. Also jede Abfrage ein Full Table Scan und die Tabelle wurde immer grösser und damit dauerte das Eintragen immer länger. Und wir als Web-User sind ja nicht gerade geduldig, wenns länger dauert, einfach noch mal Refresh drücken, und der Prozess beginnt von vorn, was das Problem weiter verschärft. Ich habe dann einen Index angelegt, das dauerte 30 Sekunden, damit war das Problem in der Datenbank behoben. Die Applikationsserver waren aber so zu, dass man sie durchstarten musste. Der Shop war insgesamt ca. 2 Stunden weg, in denen kein Umsatz generiert werden konnte. Ich bin dann zu „Gott“ und habe ihn gefragt, ob er getestet hat. Klar hat er, die Funktionalität, aber keine Mengentests. „Gott“ hat von da an immer Funktions- und Massentests gemacht. Trotzdem wurde in den höheren Etagen die Ursache in der Datenbank ausgemacht, weil die Funktion war ja fehlerfrei, die Datenbank hat länger gebraucht beim Ergebnis finden. Solche Situationen habe ich schon mehrere erlebt. Ich nenne das den „Datenbank-Knick“. Immer dann, wenn ich das Problem in der Datenbank lösen konnte, dann war die Datenbank auch am Problem „schuld“. Und wenn nicht, war sie es trotzdem.
Und dann kamen die Opensource-Datenbanken, Die lassen sich kostenlos aus dem Internet runterladen und installieren, meist mit einem Kommando, nämlich yum. Dann gibt es da noch Tools wie PHPMyAdmin (für MySQL) oder pgAdmin (PostgreSQL), ebenfalls frei installierbar. Damit kann man sich eine Datenbank erzeugen und ein paar Tabellen, den Rest überlässt man der Persistenzsschicht. Das geht alles schnell und einfach und man braucht keinen DBA. Klar, dass das die Entwickler begeistert. Und irgendwann auch die Chefs. Und die fragten sich dann auch bald: Wieso zahlen ich soviel Geld für ORACLE-Datenbank-Lizenzen?
Jetzt kam der Wind von zwei Seiten, die Entwickler warfen weiterhin und noch schneller ihre Apps über’n Zaun, diesmal mit Cassandra oder MariaDB oder PostgreSQL oder gar eine NoSQL-Datenbank als „Daten-Layer“. Das allein ist nicht das Problem. Das Problem ist dabei, dass dann im Betrieb dieser Datenbanken auftretende Performanceprobleme nicht so einfach zu lösen sind wie bei ORACLE. Ja einen Index anlegen geht da auch, hilft aber nicht immer. Und dann geht das „Gebastel“ los. Klar man kann PostgreSQL „kostenlos“ skalieren, naja Rechenleistung in der Cloud braucht es auch und die muss bezahlt werden und PostgreSQL-Skalierung On-Premise heisst Hardware-Erweiterung, die ist auch nicht unbedingt kostenlos. Dann gibt es noch eine Reihe von Erweiterungen, die man installieren kann, die kommen von verschiedenen Entwicklern und sind auch nicht alle kostenlos. D.h. man muss rausfinden, welche Extention einem hilft. Dann kann man noch die Community fragen, das kann aber etwas dauern. Oder man fragt einen Spezialisten. Das kostet auch Geld, mindestens aber Zeit. Nach meiner Erfahrung kann ich feststellen: Die Kostenwelle bei freien Datenbanken kommt später, nämlich im Betrieb, während die Kosten bei ORACLE (Lizenzen & Wartung) bei der Anschaffung, also vor dem Betrieb, kommen. Leider nimmt der Mensch aber die Anschaffungskosten stärker wahr als die Betriebskosten…. Von der anderen Seite kam die Chefetage mit der Frage: Wie kann man ORACLE durch Opensource-Datenbanken ersetzen? Ich bin auch gerade mit so einem Plan konfrontiert, der die Ablösung von ORACLE vorsieht. Wenn es selbstentwicklete Software ist, kann man versuchen, die Datenbank z.B. in PostgreSQL zu migrieren, da sich ORACLE und PostgreSQL „ähneln“. Da gibt es auch Tools für die Konvertierung. Bei Datentypen funktioniert das recht gut. Bei der Umwandlung von etwas komplexeren Views und PL/SQL geht es schon nicht mehr. Also baut man alles von Hand um, was dauert und damit kostet. Bei Datenbanken, die von Dritt-Anbieter-Apps benötigt werden, kann man nur den Hersteller fragen. Bisher habe ich dabei immer erlebt, dass solche Anfragen mindestens 50:50 ausgingen, Eine Hälfte lässt sich umstellen auf eine Opensource-Datenbank, die andere Hälfte nicht. Also bleibt einem ORACLE weiter erhalten. Hat man dann ein Engineered System (Exadata oder ODA) im Rechenzentrum stehen, wäre eine Umstellung wirtschaftlich nicht empfehlenswert, da die Lizenzkosten gleich bleiben, bei weniger Datenbanken. Damit kostet jede verbliebene Datenbank mehr als vorher. Hier sollte man eher nachdenken noch mehr ORACLE-Datenbanken auf das System zu bringen, also eher von Opensource auf ORACLE umstellen. So kann man meines Erachtens die Lizenzkosten effizient nutzen.
Leider scheint aber der Zug für solche Überlegungen abgefahren zu sein. Der Hype „Nur noch Opensource“ oder auch „Bloss nicht ORACLE“ scheint voll im Gange. Und wenn dann noch ein DBA wie ich damit kommt, der fast nur mit ORACLE gearbeitet hat, dann hören ihm erst recht weder Entwickler noch Chefs oder Entscheider zu. Naja, dass es zu dieser Situation kam, hat wohl auch ORACLE’s Haltung zur Lizenzierung von ORACLE-Produkten auf VMWare zu tun. Neben dem Einsatz von Opensource ist Virtualisierung ein weiterer Baustein zur Kosteneinsparung. Und ein grosser Player, wenn nicht der Player für Virtualisierung ist VMWare. Mit Virtualisierungssoftware ist es möglich, dass mehrere Server virtuell (sogenannte VMs = Virtuelle Maschine) auf einer Hardware ausgeführt werden. Sie teilen sich die Ressourcen (CPU, Speicher etc.), was die Kosten für die Hardware reduziert.
ORACLE steht bei VMWare (und soviel ich weiss auch bei Hyper-V von Microsoft) nun auf dem Standpunkt, dass man, wenn man z.B. eine ORACLE Datenbank auf einer VMWare-Virtualisierung laufen lässt, muss man alle Prozessoren aller VMWare-Nodes lizensieren, da die VM mit der ORACLE-Datenbank drauf theoretisch auf jedem Prozessor laufen könnte ("Oracle Partitioning Letter") . D.h. also, wenn man auf einer Hardware-Farm mit 100 CPUs virtualisiert, und man dort eine VM mit einer ORACLE-Datenbank installiert, die vielleicht 2 CPUs benötigt , muss man laut ORACLE alle 100 CPUs lizensieren. Das ist keine Kostenreduktion, sondern eine Kosten-Explosion. Nachvollziehen kann ich diese Praxis nicht ganz. Eine Lizenzpraxis, wie z.B. bei IBM’s LPAR oder der ORACLE eigenen Virtualisierung ORACLE VM, für alle Virtualisierungsanbieter würde den aktuellen Gegenwind für ORACLE erheblich abflauen lassen.
Neben dem Simplifizieren, der Kostensenkung durch Opensource und ORACLE’s komischen Lizenzregeln beim „Fremd“-Virtualisieren gibt es noch ein paar andere Gründe, warum ORACLE verteufelt wird. In den letzten 25 Jahren habe ich da schon ein paar kuriose aufgedeckt, von allein sagt einem das niemand, höchstens bei ein paar Bier am Abend und unter vier Augen. Da gab es z.B. Entwickler, die nicht wussten, wie man eine ORACLE-Datenbank installiert. Ja früher war das nicht einfach, und das war hängen geblieben, heutzutage kann ein Huhn ORACLE installieren, man muss nur ein paar Körner auf die ENTER-Taste legen., und natürlich geht das jetzt auch mit yum. Dann sollte ich an der Abschaffung von ORACLE mitwirken.Man hatte eine ExaData und wollte Oracle abschaffen ? Nach einer Weile fand ich raus, dass die ExaData nicht im eigenen Rechenzentrum stand, sondern bei einem Provider. Ja und der hatte wohl nicht so viel KnowHow in ExaData, jedenfalls liessen seine Jobgesuche für einen ExaData-Engineer drauf schliessen. Aber miteinander darüber gesprochen haben Provider und Eigner der ExaData nicht. Für den Eigner sah es so aus, als ob das ORACLE-„Zeugs“ nicht richtig funktioniert und war entsprechend sauer, natürlich auf ORACLE, Tenor: „Ein Haufen Geld und kein Service“ . Wer denkt da nicht dran, den „Krempel“ wieder los zu werden. Ja und dann gibts noch die Entwickler, die partout keine Funktionen einer Datenbank benutzen und diese lieber in JAVA nachbilden. Als Argument wird dann immer aufgeführt, dass so die Datenbank jederzeit austauschbar ist. Kann man machen, aber man verliert dabei Performance und zwar nicht nur bei ORACLE sondern mehr oder minder bei allen Datenbanken. Datenfunktionen (Analytische, OLAP usw. ) sind in Datenbanken effiizient integriert, weil nahe an den Daten. Keine Programmiersprache kann dem das Wasser reichen. Ich halte es daher für eine bessere Idee, sich bei seiner App-Entwicklung auf ein paar Datenbanken zu fokussieren, dann abber deren Datenfunktionen zu benutzen und auch deren Programmiersprache.
Für mich ist dieses ORACLE-„Bashing“ völlig unangebracht. Ich habe fast mein ganzes Berufsleben mit Datenbanken und anderen Produkten von ORACLE zu tun gehabt. Bisher gab es immer eine Lösung, entweder mit irgendwelchen Komponenten (z.B. Data Masking, InMemory, usw.) oder mit simplem Tuning-Handwerk oder mit dem ORACLE Support. Klar kostet das Lizenzen und Wartung, dafür bekommt man aber auch ein System, mit dem ein sicherer und stabiler Betrieb garantiert wird. Des Weiteren deckt ORACLE mit seiner Datenbank nahezu jeden Anwendungsbereich ab. Deswegen ist es völliger Unsinn und ein grosser Fehler , diese Datenbank von vornherein auszuschliessen. Auch das Abschaffen von ORACLE sollte überlegt sein und man sollte vorher wissen, was das für den eigenen Betrieb zeit- und kostentechnisch bedeutet. Ich hatte schon ein paar Anfragen früherer Kunden, die gern wieder auf ORACLE Datenbanken zurück wollten….. Natürlich haben alle anderen Datenbanken ob nun Opensource oder nicht auch ihre Daseinsberechtigung. Es kommt drauf an, die richtige Datenbank für den jeweiligen Zweck zu finden und mit dieser dann die App oder das System zu realisieren und dabei auch die Vorzüge der Datenbank in der Programmierung auszunutzen. Natürlich kommt man bei solchen Realisierungen an Punkte, wo man etwas nicht weiss bzgl. Datenbanzugriff oder -abfrage oder was auch immer. Das ist kein Beinbruch, dafür gibts solche Leute wie mich, die kann man alles fragen. Es gibt keine dumme Fragen nur dumme Antworten. Ich denke nur so kann man gute Projekte realisieren: zusammen ohne Aggressionen und ohne Vorurteile. Jeder macht mal Fehler: ich, der ein oder andere Entwickler, ORACLE. Egal, irgendwann merkt man es und korrigiert es …hoffe ich.
Kaum zu fassen, jetzt bin ich auch digital und online. Einige ehemalige und aktuelle DBA-Kollegen meinten, ich weiss so viel, warum schreibst Du nicht einen eigenen Blog? Über den Umgang mit ORACLE Datenbanken? Über Datenbanken allgemein?
Und ob ich jetzt wirklich so viel weiss, dass es für einen Blog reicht, weiss ich nicht. Aber gut, ich versuche es mal. Ich versuche mal, meine grauen Zellen anzustrengen und Beiträge über Probleme und deren Lösung zu schreiben, die mir in den letzten 25 Jahren über den Weg gelaufen sind. Es wird wohl dabei meist um ORACLE gehen.
Aber nicht nur. Wir werden sehen, oder genauer gesagt: ich werde sehen. Dabei werde ich mich mit WordPress anfreunden (müssen?). Man sagte mir, dass man das jetzt nimmt um eine Webseite zu designen. Naja Webseiten habe ich früher auch mal gemacht mit NetObjects und auch Webshops mit MySQL und osCommerce. Ich bin also etwas eingerostet und werde mich erst in Laufe der Zeit darein „fitzen“. Deshalb bitte ich, das vielleicht etwas simple Design dieser Seite zu entschuldigen. Ich versuche mich zu bessern.